


Modern web technology has enabled us to build increasingly powerful websites, to such an extent that nowadays we tend to call them ‘web apps’. The features and functionality of web apps mirror—and sometimes surpass—those of native mobile apps.
One of the key driving technologies of web apps is, of course, JavaScript. This platform-independent language has enabled huge innovation on the web and allows us to create awe-inspiring experiences with less and less effort.
While it can be tempting to use JavaScript platforms like React, Angular, or Vue.js to rapidly build and launch your own web apps, this also carries risk. It’s dangerously easy to create web apps that may appear to work perfectly for you, but suffer from severe issues for some of your end users.
On top of this, if you have any aspirations of ranking your web app’s content in search engines like Google , there are even more risks you need to be aware of, so you can tackle them as early as possible.
, there are even more risks you need to be aware of, so you can tackle them as early as possible.
You might also like: 4 Common SEO Myths and Tips to Avoid Them.
End user performance
Let’s start with the most important aspect of web apps’ success: how they perform for your end users. Scaling web apps is easy nowadays because you can place the burden of CPU, bandwidth, and storage squarely on your end users. Relying on client-side code means you don’t have to invest a lot in your own tech to create and launch web apps.
But this seductive paradigm means your users will suffer as a result.
Not everyone has a gleaming iPhone X with more processing power than a space shuttle. Not everyone is always on a Wi-Fi or 4G connection with 150Mbit speeds. Not everyone has gigabytes of storage to spare on their smartphone.
Building web apps that rely on your users’ devices to do most of the work only shows that you treat your users with contempt. Your app may work fine for a large chunk of your users, but many others will be frustrated by the demands your app places on their device, which will manifest in sluggish performance.
Treat your users with respect and treat their devices’ resources as scarce. Don’t make them do all of the heavy lifting—instead, optimize your app so it doesn’t require powerful CPUs or masses of bandwidth and storage, and you will be rewarded with a growing and loyal audience.
You can test how well your web app performs by using the Lighthouse auditing tool in Chrome. It’s worth checking how your app measures up and see if you can achieve top scores.

Web apps and SEO
If you’re serious about making your web app perform in search engines as well as on your users’ mobile devices, there are some best practices you should adhere to. But before we can explain these, first you need to have a basic understanding of how search engines work.
It’s very tempting to simply latch on to a blanket statement like ‘Googlebot indexes JavaScript’ and thus conclude that you’re free to use as much JavaScript as you want. In reality, things are much more complicated.
While it’s true that Google indexes JavaScript, the search engine doesn’t crawl JavaScript. This is an important distinction, and you need to grasp the difference between crawling and indexing to fully appreciate it.
Crawling vs. indexing
When Google crawls the web, it does so at unfathomable scale. Its Googlebot crawler is a massive multithreaded piece of software that crawls up to 20 billion pages a day. Because speed is crucial for an effective web crawler, Googlebot is optimized for efficiency. That means it doesn’t do much with the webpages it crawls.
The Googlebot crawler will run a page through an HTML parser to extract fresh URLs to crawl (primarily from links within <a href=”…”> tags) and add these to its crawl queue. When the crawler encounters JavaScript, it ignores it entirely. The page’s raw source code is simply downloaded and sent to the indexer—the part of Google that does most of the heavy lifting.
The indexer actually processes the page and extracts meaning from its content to build an index of the web that people can search through.
Initially, Google’s indexer also ignores a page’s JavaScript: first-pass indexing is based on the page’s HTML code. At a later stage, the indexer will try to fully render a page and execute any JavaScript. This second-pass indexing uses Google’s Web Rendering Service, which uses Chrome 41 as its rendering engine.
That’s right: Google renders the web using an old version of Chrome.
Additionally, this second stage of the indexing process isn’t very urgent. At I/O 2018, during a talk about how to make JavaScript websites search engine friendly, Google admitted that it only renders webpages ‘when resources become available’. Because rendering JavaScript can be a very CPU-intensive process, Google lacks the resources to do this in real-time. In the wild, we commonly see delays between Google crawling and fully rendering a webpage of two weeks or more.
So essentially, Google crawls raw HTML only, and has a two-stage indexing process that first looks at the HTML code and weeks later will render a page (including its JavaScript) to see what else the page might contain.
Knowing this, what is it that you need to do to ensure your web app can be easily crawled and indexed by Google?
1. Optimizing for crawling
The first step is to optimize your web app for crawling. This means making sure that web crawlers can easily read your web app’s content and find crawlable links to follow.
The first principle of crawlable web apps is to make sure every individual page that you want search engines to process has its own unique URL. When it comes to SEO, URLs are sacred. Basically, search engines rank URLs in their results. So every piece of content that has ranking value should have its own URL.
Sometimes an app will serve all its content from a single URL, relying on user interaction to update the page content. This won’t work for search engines, as even during the indexing stage they won’t perform any actions. Any content that’s hidden behind a user action, such as scrolling down or clicking a button, will be invisible for search engines.
So make sure your app uses URLs. Moreover, make sure these URLs are present in the raw (unrendered) HTML source code, preferably in the form of good old-fashioned links. Google prefers to extract URLs to crawl from <a href=”…”> tags.
If you use other methods of embedding links on your page, such as onclick events, always make sure there’s an anchor tag with an href link reference in there for search engines to crawl.
2. Optimizing for indexing
The next step is optimizing your web app for indexing. Here, the ‘P’ in PWA is absolutely crucial: it stands for Progressive, which refers to Progressive Enhancement.
Progressive Enhancement means that your web app is enhanced with JavaScript. Note ‘enhanced with’, not ‘reliant on’. JavaScript should serve to bring your app to full life—not to be the entirety of your app.
With Progressive Enhancement, there is a core of basic content for your webpages that doesn’t need any JavaScript or other technologies. This is present in your app’s raw HTML course code, and this is what Google will index first.
If there’s no basic core content for Google to index, then the indexing of your web app can be heavily delayed. Relying on full rendering of your webpage to load any content means that Google will have to wait for resources to be available to properly process your pages, and as we know this can take weeks. The entire process of crawling and indexing of your web app becomes very cumbersome for Google, and this will lead to a poor performance in search results.
By ensuring you have that core content in your webpages’ raw HTML, you prevent most of the potential issues that can occur when Google tries to crawl and index your app.
Yet there are some other aspects you need to be aware of that could throw a spanner in the works:
Blocked Resources
When Google eventually fully renders your webpages, it will need to download and process all of your pages’ resources. This includes all inline code, but also any additional resources like CSS files, images, and external JavaScript files.
Sometimes, such external resources can’t be loaded by Google because it doesn’t have access to them. Especially if a webpage’s resources reside on a different (sub)domain, it’s possible that Googlebot can’t see those resources due to robots.txt disallow rules.
You can easily verify this, either by checking in your website’s Google Search Console in the ‘Blocked Resources’ report, or by running a webpage through Google’s Mobile-Friendly Test and checking if there are any ‘Page Loading Issues’ that indicate resources that aren’t accessible for Google:
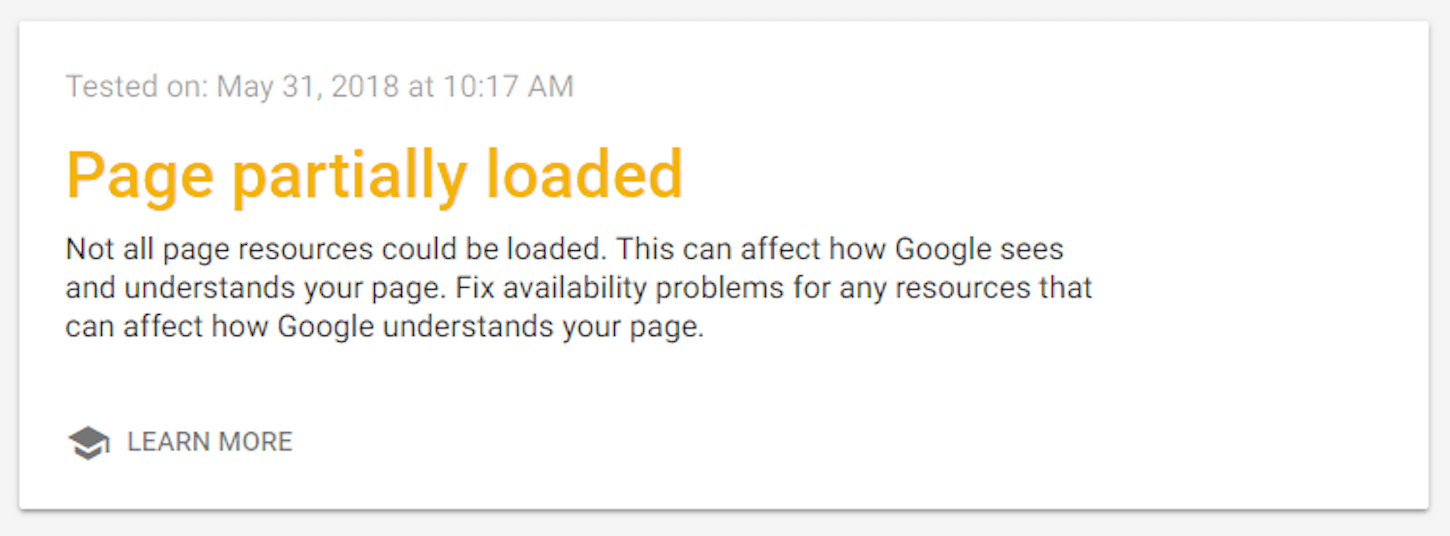
Make sure all of a page’s critical resources are accessible to Googlebot so it can download those resources and process them.
Chrome 41
Because Google uses the old Chrome 41 rendering engine to index pages, you need to be aware of that engine’s limitations. Chrome 41 lacks a lot of the features and functionality that current versions of Chrome have, and if your web app relies on these features, you may run into problems.
With CanIUse.com, we can see exactly what Chrome 41 does and doesn’t support compared to current browsers:
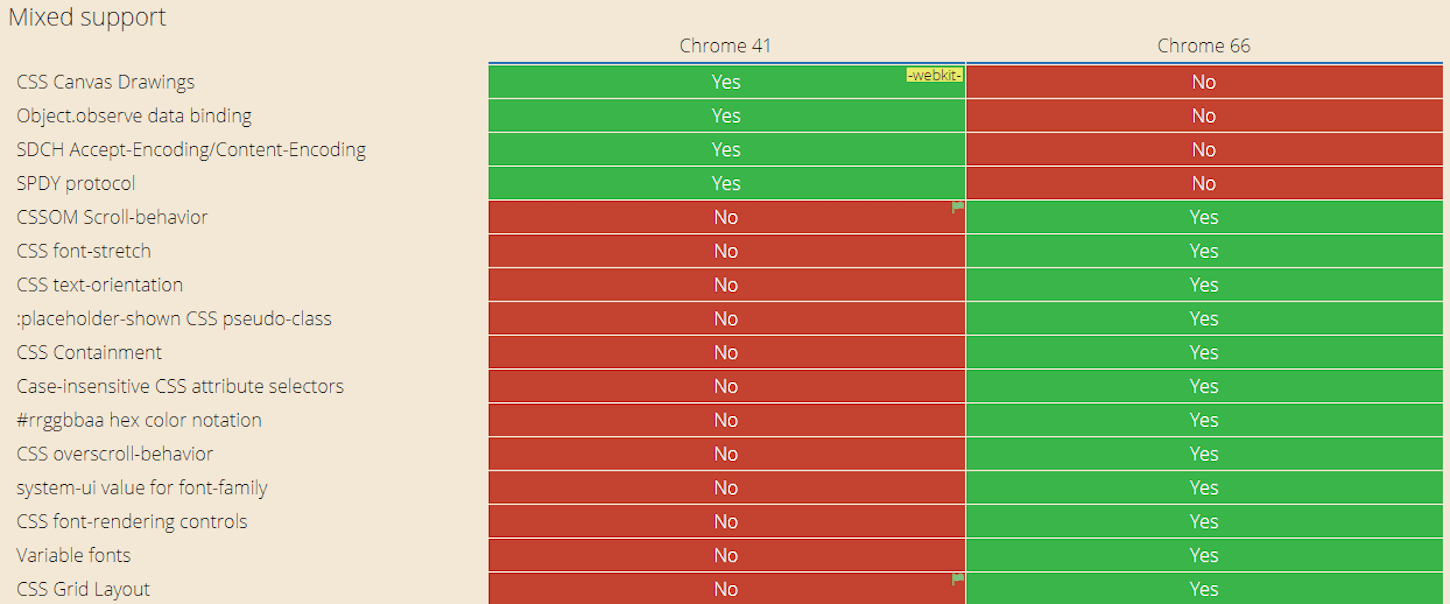
Ideally, your web app doesn’t have a critical reliance on features that lack support in Chrome 41. If some aspects of your app need up-to-date browsers, check that this won’t affect the content on the page in a crucial way. It’s okay to use modern browser features, as long as their absence doesn’t break the core content of your web app.
It can be tough to check how a page renders in Chrome 41, because we tend not to have old browser versions installed on our computers. Fortunately, we can use Google’s tools to see how a Chrome 41 rendering engine handles your pages.
First, we can use Google Search Console’s ‘Fetch as Google’ feature to see how Google’s indexer would render your page’s content. By using this tool and choosing ‘Fetch and Render’, we get a snapshot of a fully rendered page as Google sees this with its Chrome 41 rendering engine.
While this is great to check the visible aspects of a fully rendered page, it doesn’t show us the page’s computed DOM code. It can be very useful to check a page’s computed DOM as Google sees it, to ensure it contains all the right links and other relevant aspects.
For this, we can use Google’s Rich Results Test. With this tool, Google will allow us to see the source code of the fully rendered page (with Chrome 41):
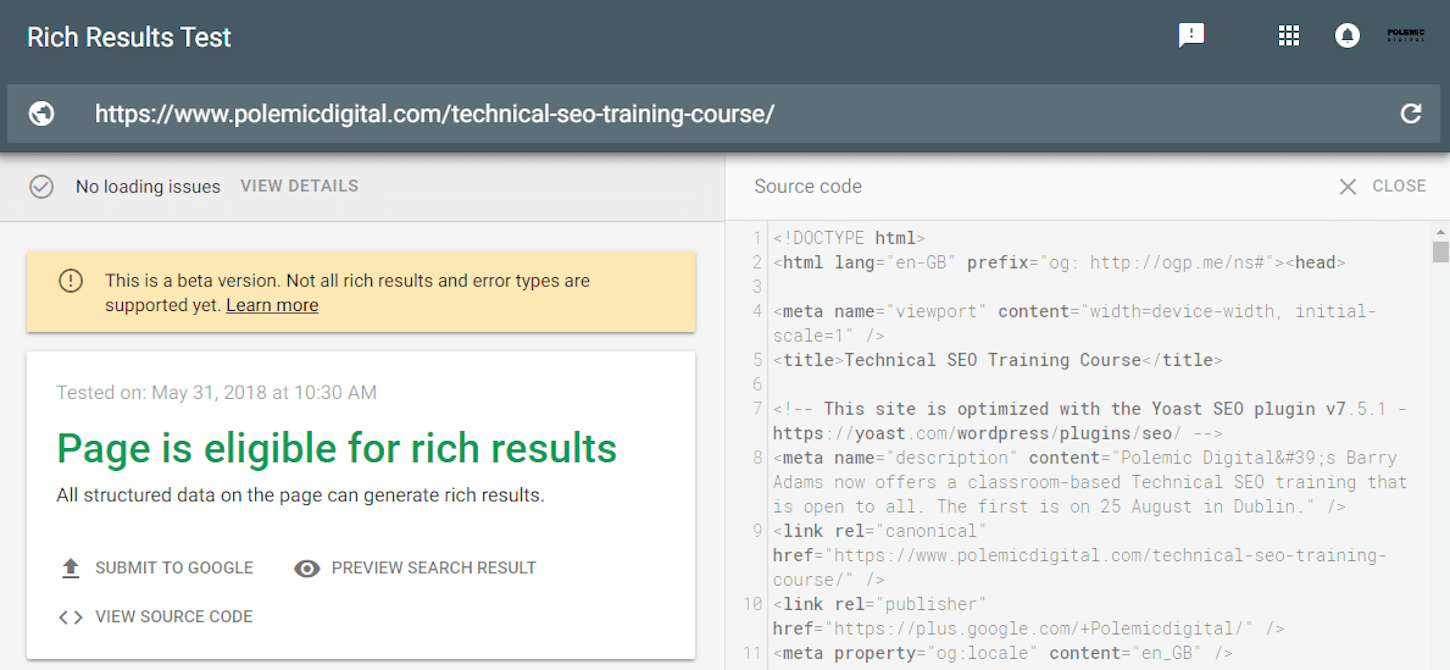
Use this tool to see what is present in the source code of a fully rendered page, so you can check if everything that you want Google to see is actually there.
Canonical and AMP
Lastly, some aspects of your webpages’ meta data need to be present in the raw HTML source, regardless of what your app later does with it. These are the page’s rel=canonical link and, if applicable, the rel=amphtml link.
Google has stated it only extracts these from the raw HTML source of a page and doesn’t look at these links if they’re injected or altered later with JavaScript. So, if you are using canonical links (and you should) and/or AMP versions of your pages, make sure these references are present in the raw HTML source of your web app’s pages.
You might also like: Canonical URLs: What Are They and Why Are They Important?
Performant PWAs in a nutshell
To summarize, making your web apps performant and indexable means you have to optimize various different aspects of your code. Don’t make users and search engines do all the work; find a balance between what you can (and should) do server-side, and where you need client-side code.
Pay heed to the ‘Progressive’ part of PWAs, and most of your SEO issues will be prevented before they even occur.
Understand how Google crawls and indexes your pages, and put the right measures in place to facilitate this. When it comes to ranking in search engines, making Google’s life easier tends to be rewarded in the long run.
Read more
Have you taken steps to make your PWAs indexable?? Share your experience in the comments below!

